Empirical Evaluations in Reinforcement Learning with pySPACE and MMLF¶
This tutorial explains how large scale empirical evaluations in the field of Reinforcement Learning (RL) can be conducted with pySPACE. For this kind of analysis the python package MMLF is required. MMLF is a general framework for problems in the domain of RL. It can be obtained from http://mmlf.sourceforge.net/.
Empirical evaluations in RL aim at comparing the performance of different agents in a (generalized) domain. The following things need to be specified:
- A specific domain OR (in case of a generalized domain) a template for a domain
- and the parameters used for instantiating specific domains from the generalized domain. Please take a look at Whiteson et al. “Generalized Domains for Empirical Evaluations in Reinforcement Learning” for more details about the concept of generalized domains.
- A parameterized definition of the agent to be used and the parameters that should be tested
- The number of independent runs that will be conducted for each combination
- of agent instantiation and domain
- The number of episodes the RL agent is allowed to learn
- The number of episodes the learned policy is evaluated
- to get a reliable estimate of its performance
This information is specified using a YAML operation specification file. One example for such a configuration file is the following:
# This operation allows to conduct empirical evaluation in Reinforcement Learning
# scenarios. It is based on the MMLF software. MMLF is written in Python and can be
# obtained at http://mmlf.sourceforge.net/. Under this URL, documentation for the MMLF
# is also available that might be useful for understanding this operation.
#
# Further information about MMLF operations can be found in the corresponding tutorial
# "Empiricial Evaluations in Reinforcment Learning with pySPACE and MMLF"
# :ref:`docs.tutorials.tutorial_interface_to_mmlf`
type: mmlf
# The path under which the MMLF package can be found
mmlf_path : "/home/user/python-packages/mmlf"
# Determines how many independent runs will be conducted for each parameter setting
runs : 1
# Determines how many episodes the agent can learn
learning_episodes : 500
# Determines how many episodes the policy learned by an agent is evaluated
# This can be set to 1 for deterministic environments, but should b e set to
# larger values for stochastic environments
test_episodes : 100
# The name of the MMLF world that will be used
# Available worlds are among others "mountain_car", "single_pole_balancing",
# "double_pole_balancing", and "maze2d.
world_name : "mountain_car"
# The template for the MMLF environment XML configuration.
# For more details, please take a look at the MMLf documentation
# The __XX__ entries are placeholders of the template which are
# instantiated by all values given in generalized_domain
# to yield concrete environments.
environment_template :
<environment environmentmodulename="mcar_env">
<configDict maxStepsPerEpisode = "500"
accelerationFactor = "__acceleration_factor__"
maxGoalVelocity = "__max_goal_velocity__"
positionNoise = "0.0"
velocityNoise = "0.0"
/>
</environment>
# In order to avoid method overfit (please take a look at the paper by
# Whiteson et al. "Generalized Domains for Empirical Evaluations in
# Reinforcement Learning" for more details), an agent should be tested
# not only in one specific instantiation of an environment, but in several
# slightly different versions of an environment. These differences
# can be obtained by varying certain parameters of the environment.
# This example will test each agent in four slightly different versions of
# the mountain car domain.
generalized_domain:
- {"__acceleration_factor__": 0.001, "__max_goal_velocity__": 0.07}
- {"__acceleration_factor__": 0.0075, "__max_goal_velocity__": 0.07}
- {"__acceleration_factor__": 0.001, "__max_goal_velocity__": 0.02}
- {"__acceleration_factor__": 0.0075, "__max_goal_velocity__": 0.02}
# The template for the MMLF agent XML configuration.
# For more details, please take a look at the MMLf documentation
# The __XX__ entries are placeholders of the template which are
# instantiated by all values given in parameter_ranges,
# parameter_settings etc. (see below) to yield concrete agents
agent_template :
<agent agentmodulename="td_lambda_agent">
<configDict gamma = "__gamma__"
epsilon = "__epsilon__"
lambda = "__lambda__"
minTraceValue = "0.5"
defaultStateDimDiscretizations = "7"
defaultActionDimDiscretizations = "5"
update_rule = "'SARSA'"
function_approximator = "dict(name = 'CMAC', learning_rate = 0.5, update_rule = 'exaggerator', number_of_tilings = 10, defaultQ = 0.0)"
policyLogFrequency = "250"
/>
</agent>
# "parameter_ranges" is used to determine the values of each parameter
# that are tested. If there is more than one parameter, then each
# possible combination (i.e. the crossproduct) is tested.
# Please be aware of the potential combinatorial explosion.
# The given example would test 3*2*3=18 different agent
# configurations!
# Alternatively, one could also specify concrete parameter combinations
# that should be tested by using "parameter_settings" instead of
# "parameter_ranges". Please look at the weka_classification_operation.yaml
# example for more details on that.
parameter_ranges:
__gamma__: [0.9, 0.99, 1.0]
__epsilon__ : [0.0, 0.1]
__lambda__: [0.0, 0.5, 0.9]
One important difference of the MMLF operation compared to other operations is that it is not necessary to define an input. This is because RL is not focused on data processing as (un-)supervised ML is. The input is indirectly described by parameters.
The given operation can be executed with the command:
python launch.py --mcore --config user.yaml --operation example/mmlf_operation.yaml
The given command will last approximately 30 minutes (depending on the speed of your machine). Each run of each combination of agent and environment instantiation will result in an individual process. The operation creates a MMLF rw-area in the operation result directory collections/operation_results/DATE. This rw-area consists of two subdirectories “config” and “logs”.
In the configuration directory, for each combination of agent and environment instantiation, three files are created: One which contains the agent configuration (prefix agent), one which contains the environment configuration (prefix env), and one which defines the world (prefix world). The suffix of the configuration files encodes the specific parameter settings. One should keep in mind that the file names might become very long (too long for some file systems). This is currently an unresolved issue.
The second important subdirectory is the “logs”-directory. In this directory, the results of the individual runs are stored. On the top level, several subdirectories are created with obscure names such as “351782211”. These numbers are basically hash values of the agent’s and environment’s parameters. This means that different parametrizations will store their results in different subdirectories but different runs with the same parametrization will go into the same subdirectory. Each of the subdirectories contains the specific agent and environment configuration used as well as one subdirectory for each run whose name is the start time of the run. Depending on the specific agent, different information might be stored in the run-directories. However, for this tutorial it is only relevant that in the subdirectory “environment_logs”, there are two files “reward” and “offline_reward”. The former contains the reward per episode the agent got during learning, the later the reward per epsiode the learned policy achieved.
At the end of the operation, the logged information are consolidated into a csv-file named results.csv. This file has the same structure as the result files generated by the weka_classification operation. Thus, the stored results can later on be analysed using the analysis operation. The csv-file is structured as followed:
For each individual run, one line is created that contains the specific values of the used agent and environment configuration. Furthermore, four columns are used for storing information about the achieved reward (reward: sequence of rewards per episode during learning, accumulated_reward : accumulated reward during learning, offline_reward: sequence of rewards per episode for learned policy, offline_accumulated_reward : accumulated reward during testing learned policy).
One thing which is important to note is the way parameter names are determined:
Most parameters of agents and environments are named as in the xml-configuration files (for instance minTraceValue stays minTraceValue). However parameters like “learning_rate” which is a parameter of the function_approximator is named “function_approximator_learning_rate” in order to avoid name-clashes. The placeholders used in the YAML configuration file are NOT used for determining names!
As mentioned above, the results are stored in the same format as the results of weka-classification operation. Thus, the following analysis operation (see also [1]) can be used to generate informative plots of the results:
type: analysis
input_path: "operation_results/20100120_09_49_27"
# We are interested in the effect of the three variable "gamma", "epsilon", and "lambda"
parameters: ["gamma", "epsilon", "lambda"]
# We are interested in the two simple metrics "accumulated_reward" and "offline_accumulated_reward"
# and in the sequence of rewards obtained during learning and testing.
metrics:
- ["reward", "sequence", {'mwa_window_length': 25}]
- "accumulated_reward"
- ["offline_reward", "sequence", {'mwa_window_length': 25}]
- "offline_accumulated_reward"
Important to note is that
The parameter names have to be those from the results.csv file and not from the parameter_ranges of the MMLF operation.
In addition to normal metrics like “accumulated_reward” and “offline_accumulated_reward” there are also two so-called “sequence metrics”. These metrics do not consist of a single float value but of a sequence of float values (in this example the rewards per episode for all episodes). This has to be indicated by a 3-tuple like the following:
["reward", "sequence", {'mwa_window_length': 25}].First comes the name of the metric in the result-csv file. Second a flag that indicates that it is a sequence metric. And third a dictionary with optional parameters; in this example the length of the moving window average used for smoothing the values (mwa_window_length).
An operation chain which would execute first the mmlf operation and then the analysis operation could be configured as follows:
# Since we start with an MMLF operation, no input is required, since the experiment setting is done in the first operation
input_path : ["dummy"]
# Each agent-environment combination is tested 10 times
# This overrides the setting from the operation specification
# file
runs: 10
# Start with a MMLF operation and analyze the results with the analysis operation
operations:
-
examples/mmlf_operation.yaml
-
examples/mmlf_analysis.yaml
Last but not least some results the analysis operation should generate for the given operation chain:
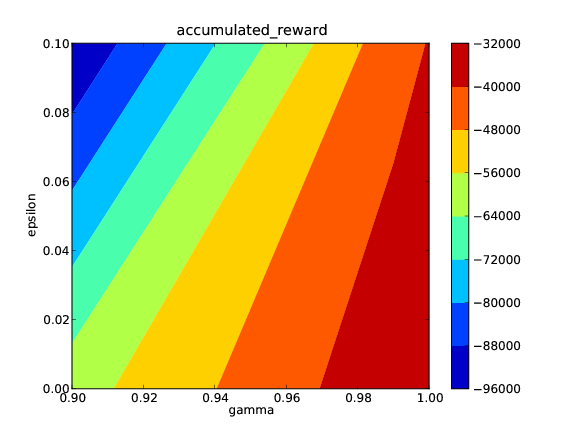
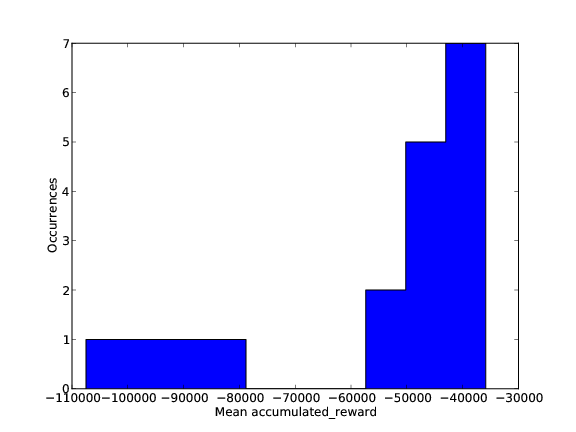
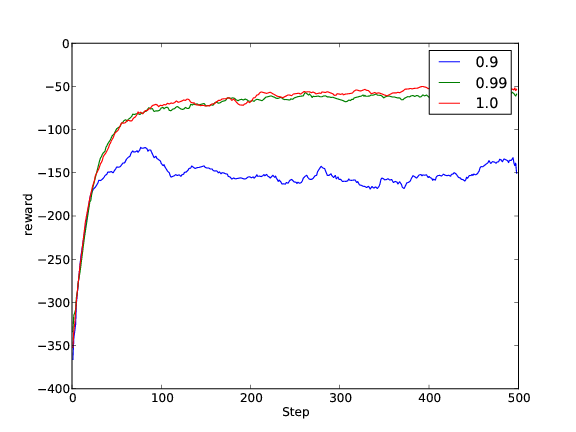
The first image shows how the accumulated reward during training changes for different values of gamma and epsilon. The second figure shows a histogram of the “accumulated reward distribution”. This figure shows some information about how susceptible the learner is to the variations of the given parameters. The last figure shows the change of obtained reward per episode over time for different values of gamma. The given figures averages over all values of lambda. If one is interested in the same figure for a specific value of lambda (say 0.0), the same figures for this condition are found in the subdirectory lambda:0.0.
Footnotes
| [1] | Alternatively, one can also use the interactive performance results analysis GUI . |