Feature Selection, Classification using WEKA¶
In this tutorial you will see how the software is working together with the popular data mining tool WEKA (see http://www.cs.waikato.ac.nz/ml/weka/). WEKA contains a lot of methods for data pre-processing e.g. filtering and for classification. They can be used within the framework through specific operation types: Weka Filter Operation and Weka Classification Operation respectively. The tutorial consists of two parts. In the first section you will see how a feature selection is performed and in the second section how a classification is performed using WEKA with pySPACE. Since you should have WEKA when you’re doing this tutorial, we will use as example-files the data that comes with WEKA.
Feature Selection with WEKA¶
A feature selection is a Weka Filter Operation in pySPACE. The main characteristics of this operation type is the transformation of one FeaturesVectorDataset summary into another. More precisely WEKA will apply a filter to all arff-files (for more information about arff file format see http://www.cs.waikato.ac.nz/~ml/weka/arff.html) in the summary. In the case of a feature selection the goal is to reduce the number of attributes.
First we have to provide the data that we want to use in the experiment in The Data Directory (storage). To get a probable evaluation of the feature selection method it is strongly recommended to divide the amount of data into training and test set. We use here the segment-challenge data set to train the feature selector and the segment-test data set for testing. In order that the datasets will be found correctly, The Data Directory (storage) should look something like this:
storage
/tutorial_data
/{arff_tutorial_dataset}
/metadata.yaml
/data_run0
features_sp0_test.arff
features_sp0_train.arff
where the metadata.yaml might be
type: feature_vector
author: Max Mustermann
date: '2009_4_5'
classes_names: [brickface,sky,foliage,cement,window,path,grass]
feature_names: [region-centroid-col, region-centroid-row, region-pixel-count,
short-line-density-5, short-line-density-2, vedge-mean, vegde-sd, hedge-mean,
hedge-sd, intensity-mean, rawred-mean, rawblue-mean, rawgreen-mean, exred-mean,
exblue-mean, exgreen-mean, value-mean, saturation-mean, hue-mean]
num_features: 19
runs: 1
splits: 1
storage_format: [arff, numeric]
data_pattern: data_run/features_sp_tt.arff
train_test: true
and features_sp0_train.arff is the renamed segment-challenge.arff file from WEKA and features_sp0_test.arff the renamed segment-test.arff file respectively. Additionally to the renaming you have to change the relation name from both arff files to the name of your collection, e.g. “{arff_tutorial_collection}”.
The second step is to specify the operation. In the subdirectory operation of The Specs Directory you’ll find the subdir weka_filtering. Here you can store your operation spec file or just modify the example one:
# An example of a WekaFilter-Operation specification file. The specified
# input is the value of the entry with the key "input_path". The weka
# template is one of the available templates stored in specs/operations/weka_templates/,
# here for example "feature_selection".
type: weka_filter
input_path: "tutorial_data"
template: feature_selection
# Parameters to specify the feature selection can be set here.
# "feature_selector" specifies the evaluation method and "ranker"
# the search method of the feature selection. "num_retained_features" is the
# number of attributes that will be kept after the filtering and reflects
# to the reduction of attributes.
# Note that 'chi_squared' or 'ranker' are abbreviation which must be defined
# in abbreviations.yaml and correspond to specific weka classes.
parameter_ranges:
# e.g. chi_squared, info_gain, gain_ratio, relief, CFS
feature_selector: ['chi_squared','info_gain','gain_ratio','relief']
ranker: ['ranker'] # e.g. ranker, greedy_stepwise, best_firstn
num_retained_features: [10] # -1 means all features are retained
# "hide_parameters" means, that this parameters will not be mapped to
# the directory names in the result structure {parameter_name/parameter-value}.
# This is suggestive e.g. when only one parameter value is used.
hide_parameters: ['ranker','num_retained_features']
Third, start e.g. by invoking:
python launch.py --mcore --configuration your_configuration_file.yaml --operation examples/weka_feature_selection.yaml
How to configure your_configuration_file.yaml please look in section Getting started. Important here is especially the correct WEKA class path.
Now four processes, one for each feature selector, are executed and and the results are stored in four result directories. In each result directory you’ll find, beside the new metadata.yaml for further processing, again the two arff files which now contain only ten attributes. In addition there is a score.txt file for every split that shows the rating of features for the specific feature selector. So you might check which attributes the different evaluators chose. To make later analysis easier there are also the input metadata.yaml, the operation spec file and the used template to start WEKA stored.
Classification with WEKA¶
The Weka Classification Operation is used to train and test a classifier with WEKA. The operation needs a FeatureVectorDataset summary as input and produces a Weka PerformanceResultSummary as output, which is immediately transformed to the software format.
The first step, again, is to provide the data for this operation. This might be very easy since we can use the same data as for the feature selection.
As second step the operation spec file has to be specified. The designated location for it is the subdirectory weka_classification in the operation directory of The Specs Directory. Here an example of this file:
# An example of a WekaClassification-Operation specification file.
# The specified input is the value of the entry with the key
# "input_path", the weka template is "classification". The available
# templates are stored in specs/operations/weka_templates/.
type: weka_classification
input_path: "tutorial_data"
template: classification
# The specific classifiers to be used within the operation can be specified
# using the keyword "parameter_settings". The example below would compare four
# different parametrizations of a linear svm (complexity either 0.1 or 1.0 and
# weight for class 2 either 1.0 or 2.0). Note that 'libsvm_lin' is an
# abbreviation which must be defined in abbreviations.yaml.
# parameter_settings:
# -
# classifier: 'libsvm_lin'
# # "ir_class_index": index of the class performance metrics are
# # calculated for; index begins with 1
# ir_class_index: 1
# complexity: 0.1
# w0: 1.0
# w1: 1.0
# -
# classifier: 'libsvm_lin'
# ir_class_index: 1
# complexity: 1.0
# w0: 1.0
# w1: 1.0
# -
# classifier: 'libsvm_lin'
# ir_class_index: 1
# complexity: 0.1
# w0: 1.0
# w1: 2.0
# -
# classifier: 'libsvm_lin'
# ir_class_index: 1
# complexity: 1.0
# w0: 1.0
# w1: 2.0
# Alternatively to specific parameter settings one could also specify ranges for
# each parameter. This is indicated by the usage of "parameter_ranges" instead of
# "parameter_settings". *parameter_ranges* are automatically converted into
# *parameter_settings* by creating the crossproduct of all parameter ranges. The
# parameter_ranges in the comment below
# result in the same parameter_setting as the one given above.
#
# parameter_ranges :
# complexity : [0.1, 1.0]
# w0 : [1.0]
# w1 : [1.0, 2.0 ]
# ir_class_index: [1]
# classifier: ['libsvm_lin']
parameter_ranges :
complexity : [0.1, 0.5, 1.0, 5.0, 10.0]
w0 : [1.0]
w1 : [1.0]
ir_class_index: [1]
classifier: ['libsvm_lin']
By using this spec file for the operation the Libsvm, a classifier that not directly comes with WEKA, is applied. You can get it on http://www.csie.ntu.edu.tw/~cjlin/libsvm/. As parameter only the complexity of the linear Libsvm will be changed. The weights for the classes will be by default 1 for all classes so you can ignore this parameters. WEKA is calculating the performance metrics like precision and recall with respect to the first class, here brickface. Finally start
python launch.py --mcore --configuration your_configuration_file.yaml --operation examples/weka_classification_operation.yaml
and consider to add the libsvm.jar path in your_configuration_file.yaml to the WEKA class paths.
In the operation_result directory you’ll find, beside the new metadata.yaml, a results.csv file where all classification results are stored. You might want to visualize the results. Therefore another Operation is used: the Analysis Operation.
type: analysis
input_path: "tutorial_data"
# here interested parameters are specified; e.g. "__Dataset__",
# "__NUM_RETAINED_FEATURES__", "__SELF_DEFINED_PARAMETER__", "Kernel_Type",
# "Complexity", "Kernel_Exponent", "Kernel_Gamma", "Kernel_Offset",
# "Kernel_Weight", "Key_Scheme_options", "Key_Scheme"
# The parameter names have to be those from the results.csv file.
parameters: ["__Complexity__", "__Template__"]
# here the metrics which the evaluation is based on are specified, e.g.
# "False_positive_rate", "False_negative_rate", "Percent_correct", "F_measure",
# "Area_under_ROC", "IR_recall", "IR_precision"
metrics: ["F_measure", "False_positive_rate", "False_negative_rate"]
In this example the DATAFLOW parameter refers to the feature selector that was used.
You can now start another operation like the Weka Filter Operation or the Weka Classification Operation before, or you do all together in an operation chain. The spec file for this chain might look like:
input_path : "tutorial_data"
operations:
-
examples/weka_feature_selection.yaml
-
examples/weka_classification_operation.yaml
-
examples/weka_analysis.yaml
and you can start it with the command:
python launch.py --mcore --configuration your_configuration_file.yaml --operation_chain examples/weka.yaml
Two of the graphics from the result directory you can see here:
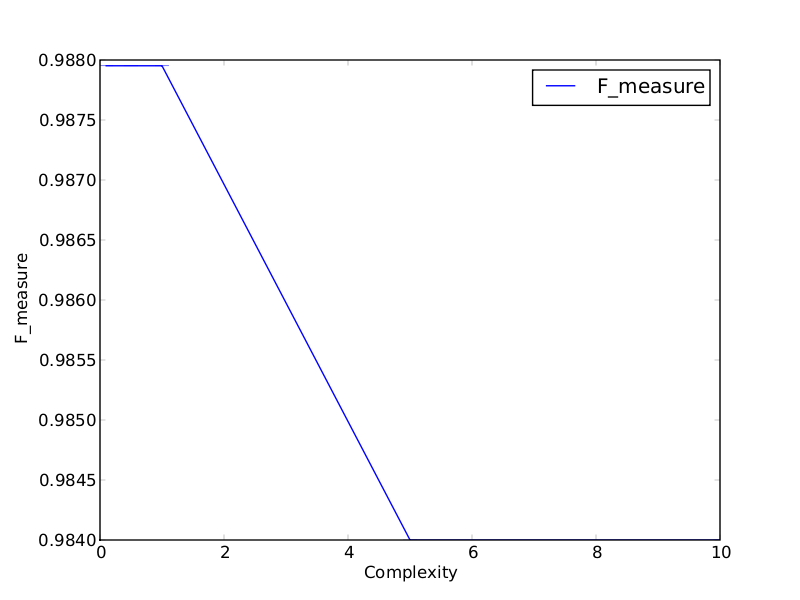
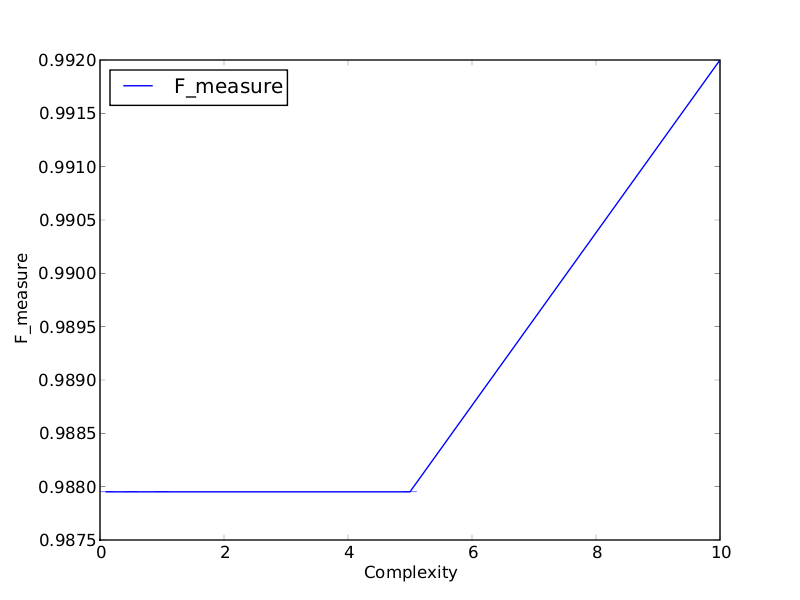
The first graphic refers to the chi-squared feature selector and the second to the relief feature selector. It is shown that with different feature sets the optimal complexity parameter of the SVM might change. In addition in this case the relief feature selector chooses attributes that result in a higher performance for the brickface class.