node_chain¶
Module: environments.chains.node_chain¶
NodeChains are sequential orders of nodes
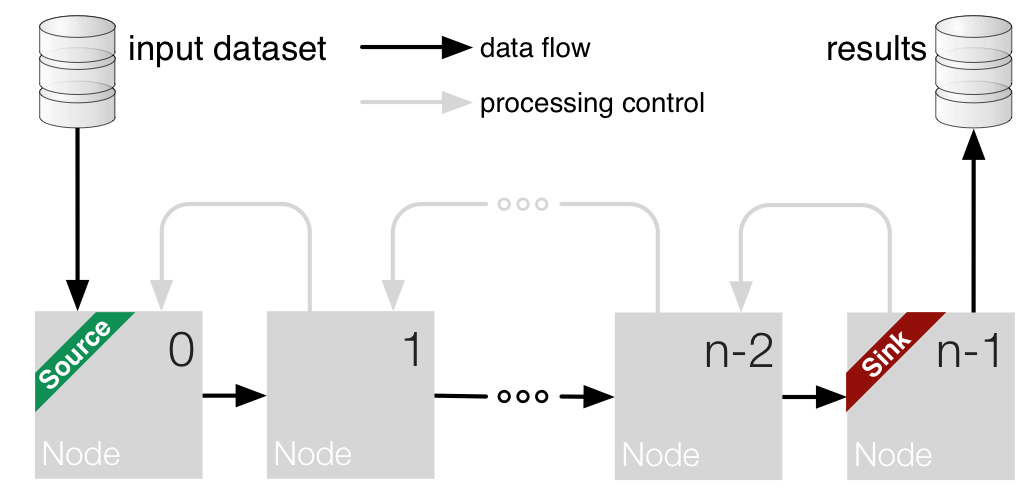
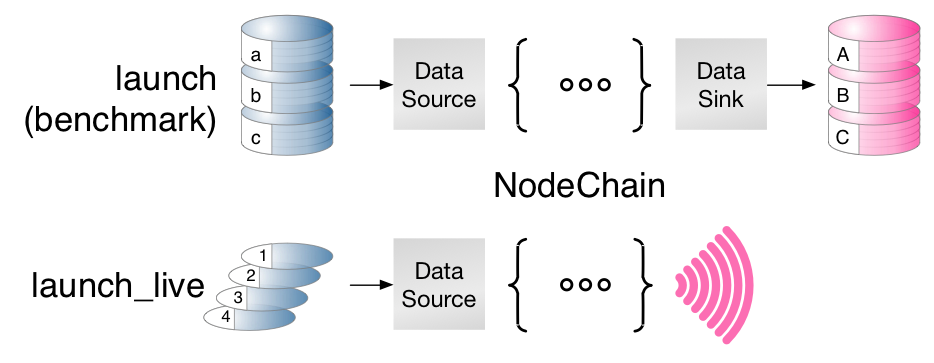
There are two main use cases:
- the application for
launch_liveand theliveusing the defaultNodeChainand
- the benchmarking with
launchusing- the
BenchmarkNodeChainwith thenode_chainoperation.
See also
nodes- List of all Nodes
node_chainoperation
This module extends/reimplements the original MDP flow class and has some additional methods like reset(), save() etc.
Furthermore it supports the construction of NodeChains and also running them inside nodes in parallel.
MDP is distributed under the following BSD license:
This file is part of Modular toolkit for Data Processing (MDP).
All the code in this package is distributed under the following conditions:
Copyright (c) 2003-2012, MDP Developers <mdp-toolkit-devel@lists.sourceforge.net>
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
* Neither the name of the Modular toolkit for Data Processing (MDP)
nor the names of its contributors may be used to endorse or promote
products derived from this software without specific prior written
permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Inheritance diagram for pySPACE.environments.chains.node_chain:

Class Summary¶
CrashRecoveryException(\*args) |
Class to handle crash recovery |
NodeChainException |
Base class for exceptions in node chains. |
NodeChainExceptionCR(\*args) |
Class to handle crash recovery |
NodeChain(node_sequence[, crash_recovery, ...]) |
Reimplement/overwrite mdp.Flow methods e.g., for supervised learning |
BenchmarkNodeChain(node_sequence) |
This subclass overwrites the train method in order to provide a more convenient way of doing supervised learning. |
NodeChainFactory |
Provide static methods to create and instantiate data flows |
SubflowHandler([processing_modality, ...]) |
Interface for nodes to generate and execute subflows (subnode-chains) |
Classes¶
CrashRecoveryException¶
-
class
pySPACE.environments.chains.node_chain.CrashRecoveryException(*args)[source]¶ Bases:
exceptions.ExceptionClass to handle crash recovery
Class Components Summary
dump([filename])Save a pickle dump of the crashing object on filename. -
__init__(*args)[source]¶ Allow crash recovery. Arguments: (error_string, crashing_obj, parent_exception) The crashing object is kept in self.crashing_obj The triggering parent exception is kept in
self.parent_exception.
-
dump(filename=None)[source]¶ Save a pickle dump of the crashing object on filename. If filename is None, the crash dump is saved on a file created by the tempfile module. Return the filename.
-
__weakref__¶ list of weak references to the object (if defined)
-
NodeChainExceptionCR¶
-
class
pySPACE.environments.chains.node_chain.NodeChainExceptionCR(*args)[source]¶ Bases:
pySPACE.environments.chains.node_chain.CrashRecoveryException,pySPACE.environments.chains.node_chain.NodeChainExceptionClass to handle crash recovery
NodeChain¶
-
class
pySPACE.environments.chains.node_chain.NodeChain(node_sequence, crash_recovery=False, verbose=False)[source]¶ Bases:
objectReimplement/overwrite mdp.Flow methods e.g., for supervised learning
Class Components Summary
__add__(other)__call__(iterable[, nodenr])Calling an instance is equivalent to call its ‘execute’ method. __contains__(item)__delitem__(key)__getitem__(key)__iadd__(other)__iter__()__len__()__repr__()__setitem__(key, value)__str__()_check_dimension_consistency(out, inp)Raise ValueError when both dimensions are set and different. _check_nodes_consistency([flow])Check the dimension consistency of a list of nodes. _check_value_type_isnode(value)_close_last_node()_execute_seq(x[, nodenr])Executes input data ‘x’ through the nodes 0..’node_nr’ included _get_required_train_args(node)Return arguments in addition to self and x for node.train. _inc_train(data[, class_label])Iterate through the nodes to train them _propagate_exception(exception, nodenr)_stop_training_hook()Hook method that is called before stop_training is called. _train_check_iterables(data_iterables)Return the data iterables after some checks and sanitizing. _train_node(data_iterable, nodenr)Train a single node in the flow. append(x)flow.append(node) – append node to flow end copy([protocol])Return a deep copy of the flow. execute([data_iterators])Process the data through all nodes extend(x)flow.extend(iterable) – extend flow by appending get_output_type(input_type[, as_string])Returns the output type of the entire node chain insert(i, x)flow.insert(index, node) – insert node before index iter_execute(iterable[, nodenr])Process the data through all nodes in the chain till nodenr iter_train(data_iterables)Train all trainable nodes in the NodeChain with data from iterator pop(...)(default last) reset()Reset the flow and obey permanent_attributes where available save(filename[, protocol])Save a pickled representation to filename set_crash_recovery([state])Set crash recovery capabilities. string_to_class(string_encoding)given a string variable, outputs a class instance train([data_iterators])Train NodeChain with data from iterator or source node trained()Returns whether the complete training is finished, i.e. -
__init__(node_sequence, crash_recovery=False, verbose=False)[source]¶ Creates the NodeChain based on the node_sequence
Note
The NodeChain cannot be executed before not all trainable nodes have been trained, i.e. self.trained() == True.
-
train(data_iterators=None)[source]¶ Train NodeChain with data from iterator or source node
The method can proceed in two different ways:
If no data is provided, it is checked that the first node of the flow is a source node. If that is the case, the data provided by this node is passed forward through the flow. During this forward propagation, the flow is trained. The request of the data is done in the last node.
If a list of data iterators is provided, then it is checked that no source and split nodes are contained in the NodeChain. these nodes only include already a data handling and should not be used, when training is done in different way. Furthermore, split nodes are relevant for benchmarking.
One iterator for each node has to be given. If only one is given, or no list, it is mapped to a list with the same iterator for each node.
Note
The iterator approach is normally not used in pySPACE, because pySPACE supplies the data with special source nodes and is doing the training automatically without explicit calls on data samples. The approach came with MDP.
-
iter_train(data_iterables)[source]¶ Train all trainable nodes in the NodeChain with data from iterator
data_iterables is a list of iterables, one for each node in the chain. The iterators returned by the iterables must return data arrays that are then used for the node training (so the data arrays are the data for the nodes).
Note that the data arrays are processed by the nodes which are in front of the node that gets trained, so the data dimension must match the input dimension of the first node.
If a node has only a single training phase then instead of an iterable you can alternatively provide an iterator (including generator-type iterators). For nodes with multiple training phases this is not possible, since the iterator cannot be restarted after the first iteration. For more information on iterators and iterables see http://docs.python.org/library/stdtypes.html#iterator-types .
In the special case that data_iterables is one single array, it is used as the data array x for all nodes and training phases.
Instead of a data array x the iterators can also return a list or tuple, where the first entry is x and the following are args for the training of the node (e.g., for supervised training).
-
trained()[source]¶ Returns whether the complete training is finished, i.e. if all nodes have been trained.
-
iter_execute(iterable, nodenr=None)[source]¶ Process the data through all nodes in the chain till nodenr
‘iterable’ is an iterable or iterator (note that a list is also an iterable), which returns data arrays that are used as input. Alternatively, one can specify one data array as input.
If ‘nodenr’ is specified, the flow is executed only up to node nr. ‘nodenr’. This is equivalent to ‘flow[:nodenr+1](iterable)’.
Note
In contrary to MDP, results are not concatenated to one big object. Each data object remains separate.
-
save(filename, protocol=-1)[source]¶ Save a pickled representation to filename
If filename is None, return a string.
Note
the pickled NodeChain is not guaranteed to be upward or backward compatible.
Note
Having C-Code in the node might cause problems with saving. Therefore, the code has special handling for the LibSVMClassifierNode.
-
get_output_type(input_type, as_string=True)[source]¶ Returns the output type of the entire node chain
Recursively iterate over nodes in flow
-
static
string_to_class(string_encoding)[source]¶ given a string variable, outputs a class instance
e.g. obtaining a TimeSeries
-
_train_node(data_iterable, nodenr)[source]¶ Train a single node in the flow.
nodenr – index of the node in the flow
-
static
_get_required_train_args(node)[source]¶ Return arguments in addition to self and x for node.train.
Arguments that have a default value are ignored.
-
_train_check_iterables(data_iterables)[source]¶ Return the data iterables after some checks and sanitizing.
Note that this method does not distinguish between iterables and iterators, so this must be taken care of later.
-
set_crash_recovery(state=True)[source]¶ Set crash recovery capabilities.
When a node raises an Exception during training, execution, or inverse execution that the flow is unable to handle, a NodeChainExceptionCR is raised. If crash recovery is set, a crash dump of the flow instance is saved for later inspection. The original exception can be found as the ‘parent_exception’ attribute of the NodeChainExceptionCR instance.
- If ‘state’ = False, disable crash recovery.
- If ‘state’ is a string, the crash dump is saved on a file with that name.
- If ‘state’ = True, the crash dump is saved on a file created by the tempfile module.
-
_execute_seq(x, nodenr=None)[source]¶ Executes input data ‘x’ through the nodes 0..’node_nr’ included
If no nodenr is specified, the complete node chain is used for processing.
-
copy(protocol=None)[source]¶ Return a deep copy of the flow.
The protocol parameter should not be used.
-
__call__(iterable, nodenr=None)[source]¶ Calling an instance is equivalent to call its ‘execute’ method.
-
_check_dimension_consistency(out, inp)[source]¶ Raise ValueError when both dimensions are set and different.
-
reset()[source]¶ Reset the flow and obey permanent_attributes where available
Method was moved to the end of class code, due to program environment problems which needed the __getitem__ method beforehand.
-
__weakref__¶ list of weak references to the object (if defined)
-
BenchmarkNodeChain¶
-
class
pySPACE.environments.chains.node_chain.BenchmarkNodeChain(node_sequence)[source]¶ Bases:
pySPACE.environments.chains.node_chain.NodeChainThis subclass overwrites the train method in order to provide a more convenient way of doing supervised learning. Furthermore, it contains a benchmark method that can be used for benchmarking.
This includes logging, setting of run numbers, delivering the result collection, handling of source and sink nodes, ...
Author: Jan Hendrik Metzen (jhm@informatik.uni-bremen.de) Created: 2008/08/18 Class Components Summary
__call__([iterable, train_instances, runs])Call execute or benchmark and return (id, PerformanceResultSummary) benchmark(input_collection[, run, ...])Perform the benchmarking of this data flow with the given collection clean_logging()Remove logging handlers if existing prepare_logging()Set up logging store_node_chain(result_dir, store_node_chain)Pickle this flow into result_dir for later usage store_persistent_nodes(result_dir)Store all nodes that should be persistent use_next_split()Use the next split of the data into training and test data -
use_next_split()[source]¶ Use the next split of the data into training and test data
This method is useful for pySPACE-benchmarking
-
benchmark(input_collection, run=0, persistency_directory=None, store_node_chain=False)[source]¶ Perform the benchmarking of this data flow with the given collection
Benchmarking is accomplished by iterating through all splits of the data into training and test data.
Parameters:
input_collection: A sequence of data/label-tuples that serves as a generator or a BaseDataset which contains the data to be processed. run: The current run which defines all random seeds within the flow. persistency_directory: Optional information of the nodes as well as the trained node chain (if store_node_chain is not False) are stored to the given persistency_directory. store_node_chain: If True the trained flow is stored to persistency_directory. If store_node_chain is a tuple of length 2—lets say (i1,i2)– only the subflow starting at the i1-th node and ending at the (i2-1)-th node is stored. This may be useful when the stored flow should be used in an ensemble.
-
__call__(iterable=None, train_instances=None, runs=[])[source]¶ Call execute or benchmark and return (id, PerformanceResultSummary)
If iterable is given, calling an instance is equivalent to call its ‘execute’ method. If train_instances and runs are given, ‘benchmark’ is called for every run number specified and results are merged. This is useful for e.g. parallel execution of subflows with the multiprocessing module, since instance methods can not be serialized in Python but whole objects.
-
store_node_chain(result_dir, store_node_chain)[source]¶ Pickle this flow into result_dir for later usage
-
prepare_logging()[source]¶ Set up logging
This method is only needed if one forks subflows, i.e. to execute them via multiprocessing.Pool
-
NodeChainFactory¶
-
class
pySPACE.environments.chains.node_chain.NodeChainFactory[source]¶ Bases:
objectProvide static methods to create and instantiate data flows
Author: Jan Hendrik Metzen (jhm@informatik.uni-bremen.de) Created: 2009/01/26 Class Components Summary
flow_from_yaml(Flow_Class, flow_spec)Creates a Flow object instantiate(template, parametrization)Instantiate a template recursively for the given parameterization replace_parameters_in_node_chain(...)-
static
flow_from_yaml(Flow_Class, flow_spec)[source]¶ Creates a Flow object
Reads from the given flow_spec, which should be a valid YAML specification of a NodeChain object, and returns this dataflow object.
Parameters
Flow_Class: The class name of node chain to create. Valid are ‘NodeChain’ and ‘BenchmarkNodeChain’. flow_spec: A valid YAML specification stream; this could be a file object, a string representation of the YAML file or the Python representation of the YAML file (list of dicts)
-
static
instantiate(template, parametrization)[source]¶ Instantiate a template recursively for the given parameterization
Instantiate means to replace the parameter in the template by the chosen value.
Parameters
Template: A dictionary with key-value pairs, where values might contain parameter keys which have to be replaced. A typical example of a template would be a Python representation of a node read from YAML. Parametrization: A dictionary with parameter names as keys and exact one value for this parameter as value.
-
__weakref__¶ list of weak references to the object (if defined)
-
static
SubflowHandler¶
-
class
pySPACE.environments.chains.node_chain.SubflowHandler(processing_modality='serial', pool_size=2, batch_size=1, **kwargs)[source]¶ Bases:
objectInterface for nodes to generate and execute subflows (subnode-chains)
A subflow means a node chain used inside a node for processing data.
This class provides functions that can be used by nodes to generate and execute subflows. It serves thereby as a communication daemon to the backend (if it is used).
Most important when inheriting from this class is that the subclass MUST be a node. The reason is that this class uses node functionality, e.g. logging, the temp_dir-variable and so on.
Parameters
processing_modality: One of the valid strings: ‘backend’, ‘serial’, ‘local’.
backend: The current backends modality is used. This is implemented at the moment only for ‘LoadlevelerBackend’ and ‘LocalBackend’. serial: All subflows are executed sequentially, i.e. one after the other. local: Subflows are executed in a Pool using pool_size cpus. This may be also needed when no backend is used. (optional, default: ‘serial’)
pool_size: If a parallelization is based on using several processes on a local system in parallel, e.g. option ‘backend’ and
pySPACEMulticoreBackendor option ‘local’, the number of worker processes for subflow evaluation has to be specified.Note
When using the LocalBackend, there is also the possibility to specify the pool size of parallel executed processes, e.g. data sets. Your total number of cpu’s should be pool size (pySPACE) + pool size (subflows).
(optional, default: 2)
batch_size: If parallelization of subflow execution is done together with the
LoadLevelerBackend, batch_size determines how many subflows are executed in one serial LoadLeveler job. This option is useful if execution of a single subflow is really short (range of seconds) since there is significant overhead in creating new jobs.(optional, default: 1)
Author: Anett Seeland (anett.seeland@dfki.de) Created: 2012/09/04 LastChange: 2012/11/06 batch_size option added Class Components Summary
execute_subflows(train_instances, subflows)Execute subflows and return result collection. generate_subflow(flow_template[, ...])Return a flow_class object of the given flow_template -
__weakref__¶ list of weak references to the object (if defined)
-
static
generate_subflow(flow_template, parametrization=None, flow_class=None)[source]¶ Return a flow_class object of the given flow_template
This methods wraps two function calls (NodeChainFactory.instantiate and NodeChainFactory.flow_from_yaml.
Parameters
flow_template: List of dicts - a valid representation of a node chain. Alternatively, a YAML-String representation could be used, which simplifies parameter replacement.
parametrization: A dictionary with parameter names as keys and exact one value for this parameter as value. Passed to NodeChainFactory.instantiate
(optional, default: None)
flow_class: The flow class name of which an object should be returned
(optional, default: BenchmarkNodeChain)
-
execute_subflows(train_instances, subflows, run_numbers=None)[source]¶ Execute subflows and return result collection.
- Parameters
training_instances: List of training instances which should be used to execute subflows.
subflows: List of BenchmarkNodeChain objects.
..note:: Note that every subflow object is stored in memory!
run_numbers: All subflows will be executed with every run_number specified in this list. If None, the current self.run_number (from the node class) is used.
(optional, default: None)
-