flow_node¶
Module: missions.nodes.meta.flow_node¶
Encapsulate complete node_chain into a single node
Inheritance diagram for pySPACE.missions.nodes.meta.flow_node:

Class Summary¶
FlowNode([nodes, load_path, trainable, ...]) |
Encapsulate a whole node chain from YAML specification or path into a single node |
UnsupervisedRetrainingFlowNode([...]) |
Use classified label for retraining |
BatchAdaptSubflowNode(load_path, \*\*kwargs) |
Load and retrain a pre-trained NodeChain for recalibration |
BacktransformationNode([mode, method, eps, ...]) |
Determine underlying linear transformation of classifier or regression algorithm |
Classes¶
FlowNode¶
-
class
pySPACE.missions.nodes.meta.flow_node.FlowNode(nodes=None, load_path=None, trainable=False, supervised=False, input_dim=None, output_dim=None, dtype=None, change_parameters=[], **kwargs)[source]¶ Bases:
pySPACE.missions.nodes.base_node.BaseNodeEncapsulate a whole node chain from YAML specification or path into a single node
The FlowNode encapsulates a whole node chain so that it can be used like a node. The encapsulated chain can either be passed directly via the nodes parameter. Alternatively, the path to a pickled node chain can be passed via load_path. In the second case, the object is loaded lazily (i.e. only when required). This is important in situations where the FlowNode is pickled again (for instance when using
MulticoreBackend).Note
When defining this node in YAML syntax, one can pass a “nodes” parameter instead of the “subflow” parameter (see exemplary call below). The value of this parameter must be a NodeChain definition in YAML syntax (properly indented). This NodeChain definition is converted into the actual “subflow” parameter passed to the constructor in the class’ static method “node_from_yaml” (overwriting the default implementation of BaseNode). Furthermore, it is determined whether trainable and supervised must be True. Thus, these parameters need not be specified explicitly.
Parameters
subflow: The NodeChain object that is encapsulated in this node. Must be provided when no load_path is given.
(semi-optional, default: None)
load_path: The path to the pickled NodeChain object that is loaded and encapsulated in this flow node. Must be given when no subflow is provided. The path string can contain phrases like __SPLIT__ - they are replaced in the super node.
(semi-optional, default: None)
trainable: If True, the nodes of the NodeChain require training, thus this node itself must be trainable.
When reading the specification, it is tested, if the subnodes need training.
(optional, default: False)
supervised: If True, the nodes require supervised training, thus this node itself must be supervised.
(optional, default: False)
input_dim: This node may require in contrast to the other nodes that the dimensionality of the input data is explicitly set. This is the case when the input dimensionality cannot be inferred from the passed subflow parameter.
(optional, default: None)
output_dim: This node may require in contrast to the other nodes that the dimensionality of the output data is explicitly set. This is the case when the output dimensionality cannot be inferred from the passed subflow parameter.
(optional, default: None)
change_parameters: List of tuple specifying, which parameters to change in the internal nodes
Each tuple is a dictionary with the keys:
node: Name of the node, parameters: dictionary of new parameters, number: optional number of occurrence in the node (default: 1). By default we assume, that node parameters and program variables are identical. This default is implemented in the BaseNode and can be overwritten by the relevant node with the function _change_parameters.
(optional, default: [])
Exemplary Call
- node : FlowNode parameters : input_dim : 64 output_dim : 1612 nodes : - node : ChannelNameSelector parameters : inverse : True selected_channels: ["EMG1","EMG2","TP7","TP8"] - node : Decimation parameters : target_frequency : 25.0 - node : FFT_Band_Pass_Filter parameters : pass_band : [0.0, 4.0] - node : Time_Domain_Features parameters : moving_window_length : 1 change_parameters : - node : ChannelNameSelector parameters : inverse : False selected_channels: ["EMG1","EMG2"]
Author: Jan Hendrik Metzen (jhm@informatik.uni-bremen.de)
Created: 2010/07/28
POSSIBLE NODE NAMES: - Flow_Node
- Flow
- FlowNode
POSSIBLE INPUT TYPES: - PredictionVector
- FeatureVector
- TimeSeries
Class Components Summary
_batch_retrain(data_list, label_list)Batch retraining for node chains _execute(data)Executes the flow on the given data vector data _get_flow()Return flow (load flow lazily if not yet loaded). _inc_train(data[, class_label])Iterate through the nodes to train them _prepare_node_chain(nodes_spec)Creates the FlowNode node and the contained chain based on the node_spec _stop_training()_train(data, label)Trains the flow on the given data vector data change_flow()get_output_type(input_type[, as_string])Get the output type of the flow input_typesis_retrainable()Retraining needed if one node is retrainable is_supervised()Returns whether this node requires supervised training is_trainable()Returns whether this node is trainable. node_from_yaml(nodes_spec)Creates the FlowNode node and the contained chain based on the node_spec present_label(label)Forward the label to the nodes reset()Reset the state to the clean state it had after its initialization set_run_number(run_number)Forward run number to flow set_temp_dir(temp_dir)Forward temp_dir to flow store_state(result_dir[, index])Stores this node in the given directory result_dir -
__init__(nodes=None, load_path=None, trainable=False, supervised=False, input_dim=None, output_dim=None, dtype=None, change_parameters=[], **kwargs)[source]¶
-
static
node_from_yaml(nodes_spec)[source]¶ Creates the FlowNode node and the contained chain based on the node_spec
-
static
_prepare_node_chain(nodes_spec)[source]¶ Creates the FlowNode node and the contained chain based on the node_spec
-
_batch_retrain(data_list, label_list)[source]¶ Batch retraining for node chains
The input data is taken, to change the first retrainable node. After the change, the data is processed and given to the next node, which is trained with the data coming from the retrained algorithm.
-
present_label(label)[source]¶ Forward the label to the nodes
buffering must be set to True only for the main node for using incremental learning in the application (live environment). The inner nodes must not have set this parameter.
-
get_output_type(input_type, as_string=True)[source]¶ Get the output type of the flow
The method calls the method with the same name from the NodeChain module where the output of an entire flow is determined
-
input_types= ['PredictionVector', 'FeatureVector', 'TimeSeries']¶
UnsupervisedRetrainingFlowNode¶
-
class
pySPACE.missions.nodes.meta.flow_node.UnsupervisedRetrainingFlowNode(decision_boundary=0, confidence_boundary=0, **kwargs)[source]¶ Bases:
pySPACE.missions.nodes.meta.flow_node.FlowNodeUse classified label for retraining
All the other functionality is as described in
FlowNode.Parameters
confidence_boundary: Minimum distance to decision boundary which is required for retraining. By default every result is used. For regression algorithms, this option cannot be used.
(optional, default: 0)
decision_boundary: Threshold for decision used for calculating classifier confidence.
(optional, default: 0)
See also
Exemplary Call
- node : UnsupervisedRetrainingFlow parameters : retrain : True nodes : - node : 2SVM parameters : retrain : True
Author: Mario Michael Krell (mario.krell@dfki.de)
Created: 2015/02/07
POSSIBLE NODE NAMES: - UnsupervisedRetrainingFlowNode
- UnsupervisedRetrainingFlow
POSSIBLE INPUT TYPES: - PredictionVector
- FeatureVector
- TimeSeries
Class Components Summary
_inc_train(data[, class_label])Execute for label guess and retrain if appropriate node_from_yaml(nodes_spec)Create the FlowNode node and the contained chain
BatchAdaptSubflowNode¶
-
class
pySPACE.missions.nodes.meta.flow_node.BatchAdaptSubflowNode(load_path, **kwargs)[source]¶ Bases:
pySPACE.missions.nodes.meta.flow_node.FlowNodeLoad and retrain a pre-trained NodeChain for recalibration
This node encapsulates a whole NodeChain so that it can be used like a node. The path to a pickled NodeChain object has to be passed via load_path. The NodeChain object is loaded lazily (i.e. only when required). This is important in situations where this node is pickled as part of a NodeChain again (for instance when using
multicore).In contrast to the FlowNode, this node allows also to retrain the loaded NodeChain to novel training data. All nodes of the loaded NodeChain for which retrain is set
Trueare provided with the training data. Before this, the method “start_retraining” is called on this node. The training data is then provided to the “_inc_train” method.Parameters
load_path: The path to the pickled NodeChain object that is loaded and encapsulated in this node. This parameter is not optional! Exemplary Call
- node : BatchAdaptSubflow parameters : load_path : "some_path"
Author: Mario Krell (mario.krell@dfki.de)
Created: 2012/06/20
POSSIBLE NODE NAMES: - Batch_Adapt_Subflow
- BatchAdaptSubflow
- BatchAdaptSubflowNode
POSSIBLE INPUT TYPES: - PredictionVector
- FeatureVector
- TimeSeries
Class Components Summary
_stop_training()_train(data, label)Expects the nodes to buffer the training samples, when they are executed on the data. input_typesnode_from_yaml(nodes_spec)Create the FlowNode node and the contained chain -
_train(data, label)[source]¶ Expects the nodes to buffer the training samples, when they are executed on the data.
-
input_types= ['PredictionVector', 'FeatureVector', 'TimeSeries']¶
BacktransformationNode¶
-
class
pySPACE.missions.nodes.meta.flow_node.BacktransformationNode(mode='linear', method='central_difference', eps=2.2000000000000002e-16, store_format=None, **kwargs)[source]¶ Bases:
pySPACE.missions.nodes.meta.flow_node.FlowNodeDetermine underlying linear transformation of classifier or regression algorithm
The resulting linear transformation can be accessed with the method: get_previous_transformations of the following node, e.g., for visualization and sensor ranking. It is stored in the same format as the input data.
Warning
This node makes sense if and only if the underlying transformations are linear. For nonlinear transformations a more generic approach needs to be implemented. This implementation is not using direct access to the internal algorithms but determining the transformation by testing a large number of samples, which is not efficient but most generic.
Warning
Currently this node requires stationary processing and does not catch the changing transformation from incremental learning.
References
main source: Backtransformation author Krell, M. M. and Straube, S. journal Advances in Data Analysis and Classification title Backtransformation: a new representation of data processing chains with a scalar decision function year 2015 doi 10.1007/s11634-015-0229-3 pages 1-25 Parameters
See also
eps: the step of the difference method
 . Should be set manually for each
differentiation
. Should be set manually for each
differentiation(default: 2.2e-16)
method: the method that should be used for the derivation. The available methods are encoded as strings
- Forward difference method ->
method="forward_difference" - Central difference method ->
method="central_difference" - Central difference method using a half step ->
method="central_difference_with_halfstep"
mode: the method used to obtain the backtransformation. The choice of method depends to the current dataset and hence
- Linear, affine datasets ->
mode="linear" - Non-linear datasets ->
mode="nonlinear"
store_format: specify the format in which the data is to be stored. The options here are:
- txt file - this file is generated automatically
- using numpy.savetxt
- pickle file - this file is generated using pickle.dump
- mat file - saved using the scipy matlab interface
If no format is specified, no file will be stored.
(optional, default: None)
Exemplary Call
- node : Backtransformation parameters : nodes : - node : FFTBandPassFilter parameters : pass_band : [0.0, 4.0] - node : TimeDomainFeatures - node : LinearDiscriminantAnalysisClassifier
Author: Mario Michael Krell
Created: 2013/12/24
POSSIBLE NODE NAMES: - BacktransformationNode
- Backtransformation
POSSIBLE INPUT TYPES: - TimeSeries
- FeatureVector
Class Components Summary
_execute(data)Determine example at first call, forward normal processing _inc_train(data[, class_label])This method is not yet implemented _stop_training()Update covariance matrix and forward training _train(data, label)Update covariance matrix and forward training central_difference_method(sample)implementation of the central difference method central_difference_with_halfstep_method(sample)implementation of the central difference method with a half step forward_difference_method(sample)implementation of the forward difference method generate_affine_backtransformation()Generate synthetic examples and test them to determine transformation get_derivative([sample])obtain the derivative of the entire transformation get_own_transformation([sample])Return the transformation parameters get_sensor_ranking()Transform the transformation to a sensor ranking by adding the respective absolute values input_typesnode_from_yaml(nodes_spec)Creates the FlowNode node and the contained chain based on the node_spec normalization(sample)normalizes the results of the transformation to the same norm as the input store_state(result_dir[, index])Store the results -
input_types= ['TimeSeries', 'FeatureVector']¶
-
__init__(mode='linear', method='central_difference', eps=2.2000000000000002e-16, store_format=None, **kwargs)[source]¶
-
generate_affine_backtransformation()[source]¶ Generate synthetic examples and test them to determine transformation
This is the key method!
-
normalization(sample)[source]¶ normalizes the results of the transformation to the same norm as the input
Principle
The function first computes the norm of the input and then applies the same norm to the self.trafo variable such that the results will be on the same scale
Note
If either the input or the derivative have not been computed already the node will will raise an IOError.
-
get_derivative(sample=None)[source]¶ obtain the derivative of the entire transformation
The method is just a wrapper for different methods of derivation that are called by the method. The first order derivative is saved to a variable called
self.trafoand can be visualised using specific methodsThe methods used in the following pieces of code are described in Numerical Methods in Engineering with Python by Jaan Kiusalaas. Namely, the three methods implemented here are:
- Forward difference method
- Central difference method
- Central difference method using a half step
More details about the implementations can be found in the descriptions of the functions
Parameters
sample: the initial values on which the derivative is to be computed. If no sample is provided, the default self.examplevariable is used.(default: None)
-
forward_difference_method(sample)[source]¶ implementation of the forward difference method
Principle
The principle applied by this method of numerical differentiation is
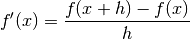
where
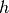 is the step of the differentiation that is computed
as
is the step of the differentiation that is computed
as 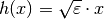 for
for 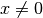 and
and
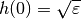 for
for 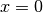 .
.The differentiation method distinguishes between
FeatureVectorandTimeSeriesinputs and applies the derivative according to the input type.Parameters
sample: the initial value used for the derivation Note
Out of the three numerical differentiation methods, this one has the least overhead. Nonetheless, this method is less accurate than the half step method.
-
central_difference_method(sample)[source]¶ implementation of the central difference method
Principle
The principle applied by the central difference method is
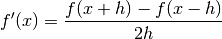
where
is the step of the differentiation that is computed
as for and
for .Parameters
sample: the initial value used for the derivation
-
central_difference_with_halfstep_method(sample)[source]¶ implementation of the central difference method with a half step
Principle
The principle applied by the central difference method with a half step is
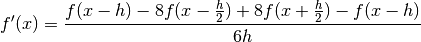
where
is the step of the differentiation that is computed
as for and
for .Parameters
sample: the initial value used for the derivation Note
This method is the most accurate differentiation method but also has the greatest overhead.
-
get_sensor_ranking()[source]¶ Transform the transformation to a sensor ranking by adding the respective absolute values
This method is following the principles as implemented in
RegularizedClassifierBase. There might be some similarities in the code.
-
static
node_from_yaml(nodes_spec)[source]¶ Creates the FlowNode node and the contained chain based on the node_spec
-
store_state(result_dir, index=None)[source]¶ Store the results
This method stores the transformation matrix, the offset, the covariance matrix and the channel names. The store_format variable must be set to either of the 3 corresponding formats: txt, pickle or mat. If the store_format variable is None, the output will not be stored.
- Forward difference method ->