base_node¶
Module: missions.nodes.base_node¶
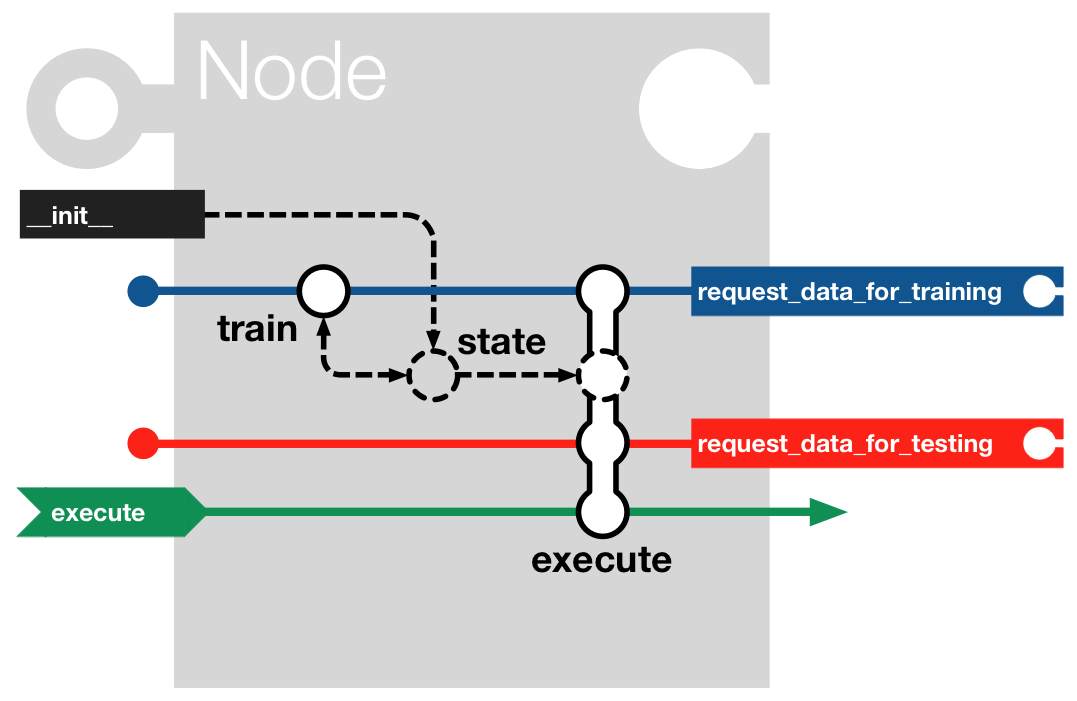
Skeleton for an elemental transformation of the signal
This includes some exception and metaclass handling, but the most important part
is the BaseNode.
Note
This module includes a reimplementation of the MDP node class that is better suited for the purposes of pySPACE. For instance it provides methods to allow the benchmarking of supervised training, storing, loading, cross validation, logging ... Furthermore, it takes care for the totally different data types, because in our case, the input data is 2-dimensional. These differences in concept are quite essential and resulted in creating an ‘own’ implementation, comprising the code into one module, instead of keeping the inheritance of the MDP node class. Nevertheless a lot of code was copied from this great library.
| Author: | Jan Hendrik Metzen (jhm@informatik.uni-bremen.de) |
|---|---|
| Created: | 2008/11/25 |
MDP (version 3.3) is distributed under the following BSD license:
This file is part of Modular toolkit for Data Processing (MDP).
All the code in this package is distributed under the following conditions:
Copyright (c) 2003-2012, MDP Developers <mdp-toolkit-devel@lists.sourceforge.net>
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
* Neither the name of the Modular toolkit for Data Processing (MDP)
nor the names of its contributors may be used to endorse or promote
products derived from this software without specific prior written
permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
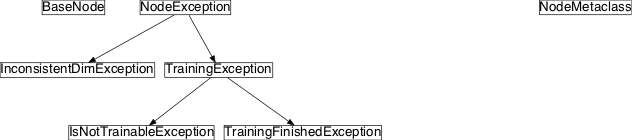
Inheritance diagram for pySPACE.missions.nodes.base_node:
Class Summary¶
NodeException |
Base class for exceptions in Node subclasses. |
InconsistentDimException |
Raised when there is a conflict setting the dimensions |
TrainingException |
Base class for exceptions in the training phase. |
TrainingFinishedException |
Raised when the Node.train method is called although the training phase is closed. |
IsNotTrainableException |
Raised when the Node.train method is called although the node is not trainable. |
NodeMetaclass |
General meta class for future features |
BaseNode([store, retrain, input_dim, ...]) |
Main base class for nodes which forwards data without processing |
Classes¶
InconsistentDimException¶
-
class
pySPACE.missions.nodes.base_node.InconsistentDimException[source]¶ Bases:
pySPACE.missions.nodes.base_node.NodeExceptionRaised when there is a conflict setting the dimensions
Note that incoming data with conflicting dimensionality raises a normal NodeException.
TrainingException¶
-
class
pySPACE.missions.nodes.base_node.TrainingException[source]¶ Bases:
pySPACE.missions.nodes.base_node.NodeExceptionBase class for exceptions in the training phase.
TrainingFinishedException¶
-
class
pySPACE.missions.nodes.base_node.TrainingFinishedException[source]¶ Bases:
pySPACE.missions.nodes.base_node.TrainingExceptionRaised when the Node.train method is called although the training phase is closed.
IsNotTrainableException¶
-
class
pySPACE.missions.nodes.base_node.IsNotTrainableException[source]¶ Bases:
pySPACE.missions.nodes.base_node.TrainingExceptionRaised when the Node.train method is called although the node is not trainable.
BaseNode¶
-
class
pySPACE.missions.nodes.base_node.BaseNode(store=False, retrain=False, input_dim=None, output_dim=None, dtype=None, kwargs_warning=True, **kwargs)[source]¶ Bases:
objectMain base class for nodes which forwards data without processing
It provides methods to allow the benchmarking of supervised training, storing, loading, cross validation, logging, ... Furthermore, it takes care for different data types. The input data is currently two-dimensional. It can be:
TimeSeriesorFeatureVectororPredictionVector- which all inherit from a common
BaseData.
In the following parameters are introduced which do not give any functionality but which could generally be used by inheriting nodes.
Parameters
input_dim: Dimension(s) of the input data. By default determined automatically.
(optional, default: None)
output_dim: Dimension(s) of the output data. By default determined automatically.
(optional, default: None)
dtype: Data type of the data array. By default determined automatically.
(optional, default: None)
keep_in_history: This parameter is a specialty, which comes with the
BaseData. The execution result of the node is copied into the history parameter of the object. Additionally, the specs of the object receive an entry labeled ‘ node_specs’ containing a dictionary of additional information from the saving node.Especially
visualizationnodes may use this functionality to visualize the change of the processing of the data.(optional, default: False)
load_path: This is the standard variable to load processing information for the node especially from previous seen data.
Examples for the usage, are the loading of spatial filters, classifiers or feature normalizations. If a parameter load_path is provided for any node, the node is able to replace some keywords.
So far implemented replacements:
__RUN__: current run number __SPLIT__: current split number Be aware that corresponding split and run numbers don’t necessarily mean that you’re operating on the same data.
Especially if cross validations generated the splits, there is no reason to believe that the current splitting has anything to do with a previous one!
Note
The keywords __INPUT_DATASET__ and __RESULT_DIRECTORY__ can also be used. The replacement of these keyword is done in the
NodeChainOperation.(optional, default: None)
store: If the node parameter store is set to ‘True’, before each reset the internal state of the node is stored (pickled) with the store_state method.
(optional, default: False)
retrain: If your node has the method _inc_train and you want to use incremental training during testing or application phase, this parameter has to be set to True. After processing the data, the node will immediately get the label to learn changes in the data.
For more subtle retraining in the online application, you will additionally have to use the parameter buffering (‘True’) to save all occurring samples in the testing phase. The retraining is then activated by calling the method present_label(label):
If the the label is None, only the first buffered element is deleted. This is used, if we don’t get a label, if we are insecure of the true label or if we simply do not want to retrain on this sample. In the other case, the presented label belongs to the first buffered element, which is then given to the _inc_train method together with its label. Afterwards the buffered element is deleted.
The method could be called in different ways in a sink node, to simulate different ways of getting labels and different ways of incremental learning.
Furthermore, it could used by node_chain_scripts as they can be found in the
liveenvironment, where we have the real situation, that we have to check after the classification, what was the right label of the data.Note
Before using this parameter you should always check, if the node is able for incremental learning!
(optional, default: False)
buffering: This switch is responsible for real time incremental learning of the node in applications (live environment), by mainly buffering all samples in the execute method in the testing phase.
If buffering is set to ‘True’, the retrain parameter should also be and the node must have an _inc_train method. Furthermore the present_label method must be called externally. Otherwise you will run into memory issues.
For more details see the documentation of the retrain parameter.
(optional, default: False)
zero_training: This enforces the node to be not trained, though it is trainable.
Warning
For usage in nodes, the algorithms need to define proper defaults in the initialization, e.g. by using the load_path parameter.
(optional, default: True)
kwargs_warning: Raise a warning if unexpected keyword arguments are given.
(optional, default: True)
Implementing your own Node
For finding out, how to implement your own node, have a look at the
templates.Exemplary Call
- node : Noop parameters : keep_in_history : True
Input: Any (e.g. FeatureVector)
Output: Any1 (e.g. FeatureVector)
Author: Mario Michael Krell and many more (krell@uni-bremen.de)
Created: before 2008/09/28
POSSIBLE NODE NAMES: - Noop
- BaseNode
- Base
POSSIBLE INPUT TYPES: - PredictionVector
- FeatureVector
- TimeSeries
Class Components Summary
__call__(x, \*args, \*\*kwargs)Calling an instance of Node is equivalent to calling its execute method. __del__()__getstate__()Return a pickable state for this object __hyperparameters__repr__()__setstate__(sdict)Restore object from its pickled state __str__()_batch_retrain(data_list, label_list)Interface for retraining with a set of data _change_parameters(parameters)Overwrite parameters of a node e.g. _check_input(x)Check the input_dim and array consistency _check_output(y)_check_train_args(x, \*args, \*\*kwargs)Checks if the arguments are correct for training _execute(x)Elemental processing step (key component) _get_supported_dtypes()Return the list of dtypes supported by this node. _get_train_seq()_get_train_set([use_test_data])Returns the data that can be used for training _if_training_stop_training()_inc_train(data[, class_label])Method to be overwritten by subclass for incremental training after initial training _log(message[, level])Log the given message into the logger of this class _pre_execution_checks(x)This method contains all pre-execution checks. _refcast(x)Helper function to cast arrays to the internal dtype. _set_dtype(t)_set_input_dim(n)_set_output_dim(n)_stop_training(\*args, \*\*kwargs)Called method after the training data went through the node _trace(x, key_str)Every call of this function creates a time-stamped log entry _train(x)Give the training data to the node _train_seqList of tuples: copy([protocol])Return a deep copy of the node. dtypeeval_dict(dictionary)Check dictionary entries starts and evaluate if needed execute(x[, in_training])Project the data by using matrix product with the random matrix get_current_train_phase()Return the index of the current training phase. get_dtype()Return dtype. get_input_dim()Return input dimensions. get_input_types([as_string])Return all available input types from the node get_metadata(key)get_output_dim()Return output dimensions. get_output_type(input_type[, as_string])Return output type depending on the input_type get_own_transformation([sample])If the node has a transformation, it should overwrite this method get_previous_execute(data[, number])Get execution from previous nodes on data get_previous_transformations([sample])Recursively construct a list of (linear) transformations get_remaining_train_phase()Return the number of training phases still to accomplish. get_source_file_name()Returns the name of the source file. get_supported_dtypes()Return dtypes supported by the node as a list of numpy dtype objects. has_multiple_training_phases()Return True if the node has multiple training phases. increase_split_number()Method for increasing split number (needed for access by meta nodes) input_dimInput dimensions input_typesis_retrainable()Returns if node supports retraining is_sink_node()Returns if this node is a sink node that gathers results is_source_node()Returns whether this node is a source node that can yield data is_split_node()Returns whether this is a split node. is_supervised()Returns whether this node requires supervised training is_trainable()Return True if the node can be trained, False otherwise is_training()Return True if the node is in the training phase, False otherwise. node_from_yaml(node_spec)Creates a node based on the dictionary node_spec output_dimOutput dimensions perform_final_split_action()Perform automatic action when the processing of the current split is finished. present_label(label)Wrapper method for incremental training in application case (live) process()Processes all data that is provided by the input node register_input_node(node)Register the given node as input replace_keywords_in_load_path()Replace keywords in the load_path parameter request_data_for_testing()Returns data for testing of subsequent nodes of the node chain request_data_for_training(use_test_data)Returns data for training of subsequent nodes of the node chain reset()Reset the state of the object to the clean state it had after its initialization reset_attribute(attribute_string)Reset a single attribute with its previously saved permanent state save(filename[, protocol])Save a pickled serialization of the node to filename. set_dtype(t)Set internal structures’ dtype. set_input_dim(n)Set input dimensions. set_output_dim(n)Set output dimensions. set_permanent_attributes(\*\*kwargs)Add all the items of the given kwargs dictionary as permanent attributes of this object set_run_number(run_number)Informs the node about the number of the current run set_temp_dir(temp_dir)Give directory name for temporary data saves start_retraining()Method called for initialization of retraining stop_training(\*args, \*\*kwargs)Generate a sparse random projection matrix store_state(result_dir[, index])Stores this node in the given directory result_dir string_to_class(string_encoding)given a string variable, outputs a class instance supported_dtypesSupported dtypes test_retrain(data, label)Wrapper method for offline incremental retraining train(x, \*args, \*\*kwargs)Update the internal structures according to the input data x. train_sweep(use_test_data)Performs the actual training of the node. use_next_split()Use the next split of the data into training and test data. -
__metaclass__¶ alias of
NodeMetaclass
-
__init__(store=False, retrain=False, input_dim=None, output_dim=None, dtype=None, kwargs_warning=True, **kwargs)[source]¶ This initialization is necessary for every node
So make sure, that you use it via the super method in each new node. The method cares for the setting of the basic parameters, including parameters for storing, and handling of training and test data.
-
buffering= None¶ parameter for retraining in application see present_label
-
caching= None¶ Do we have to remember the outputs of this node for later reuse?
-
_train(x)[source]¶ Give the training data to the node
If a node is trainable, this method is called and has to be implemented. Optionally the
_stop_training()method can be additionally implemented.
-
_stop_training(*args, **kwargs)[source]¶ Called method after the training data went through the node
It can be overwritten by the inheriting node. Normally, the
_train()method only collects the data and this method does the real (batch) training.By default this method does nothing.
-
_execute(x)[source]¶ Elemental processing step (key component)
This method should be overwritten by the inheriting node. It implements the final processing of the data of the node.
By default the data is just forwarded.
Some nodes only visualize or analyze training data or only handle the data sets without changing the data and so they do not need this method.
-
_check_train_args(x, *args, **kwargs)[source]¶ Checks if the arguments are correct for training
Implemented by subclasses if needed.
-
_inc_train(data, class_label=None)[source]¶ Method to be overwritten by subclass for incremental training after initial training
-
get_own_transformation(sample=None)[source]¶ If the node has a transformation, it should overwrite this method
The format should be:
(main transformation, offset and further parameters, relevant names, transformation type)
-
classmethod
get_input_types(as_string=True)[source]¶ Return all available input types from the node
Parameters
as_string: Tells the method whether it should return a string encoding of the type or a class instance (default: True)
Note
Strings have less overhead than class instances
-
classmethod
get_output_type(input_type, as_string=True)[source]¶ Return output type depending on the input_type
Parameters
as_string: Tells the method whether it should return a string encoding of the type or a class instance (default: True)
input_type: The input type of the node. In most cases, the input depends on the input and can not be inferred from the algorithm category. Note
Strings have less overhead than class instances and that is why they are normally used in routine operations
By default the input type is assumed to be the same as the output type, except for classification, feature_generation and type_conversion. For any other algorithm type, especially for meta nodes, this method needs to be overwritten. Otherwise, a warning will occur.
-
static
string_to_class(string_encoding)[source]¶ given a string variable, outputs a class instance
e.g., obtaining a TimeSeries
>>> result = BaseNode.string_to_class("TimeSeries") >>> print type(result) <class 'pySPACE.resources.data_types.time_series.TimeSeries'>
-
_check_input(x)[source]¶ Check the input_dim and array consistency
Here input_dim are the dimensions of the input array
-
_get_supported_dtypes()[source]¶ Return the list of dtypes supported by this node.
The types can be specified in any format allowed by numpy dtype.
-
set_dtype(t)[source]¶ Set internal structures’ dtype.
Perform sanity checks and then calls self._set_dtype(n), which is responsible for setting the internal attribute self._dtype.
Note
Subclasses should overwrite self._set_dtype when needed.
-
get_supported_dtypes()[source]¶ Return dtypes supported by the node as a list of numpy dtype objects.
Note that subclasses should overwrite self._get_supported_dtypes when needed.
-
supported_dtypes¶ Supported dtypes
-
dtype¶
-
static
eval_dict(dictionary)[source]¶ Check dictionary entries starts and evaluate if needed
Evaluation is switched on, by using
eval(statement)to evaluate the statement. Dictionary entries are replaced with evaluation result.Note
No additional string mark up needed, contrary to normal Python evaluate syntax
-
set_permanent_attributes(**kwargs)[source]¶ Add all the items of the given kwargs dictionary as permanent attributes of this object
Permanent attribute are reset, when using the reset method. The other attributes are deleted.
Note
Parameters of the basic init function are always set permanent.
Note
The memory of permanent attributes is doubled. When having large objects, like the data in source nodes, you should handle this by overwriting the reset method.
The main reason for this method is the reset of nodes during cross validation. Here the parameters of the algorithms have to be reset, to have independent evaluations.
-
reset()[source]¶ Reset the state of the object to the clean state it had after its initialization
Note
Attributes in the permanent state are not overwritten/reset. Parameters were set into permanent state with the method: set_permanent_attributes.
-
reset_attribute(attribute_string)[source]¶ Reset a single attribute with its previously saved permanent state
-
set_run_number(run_number)[source]¶ Informs the node about the number of the current run
Per default, a node is not interested in the run number and simply hands the information back to its input node. For nodes like splitter that are interested in the run_number, this method can be overwritten.
-
get_source_file_name()[source]¶ Returns the name of the source file.
This works for the Stream2TimeSeriesSourceNode. For other nodes None is returned.
-
perform_final_split_action()[source]¶ Perform automatic action when the processing of the current split is finished.
This method does nothing in the default case, but can be overwritten by child nodes if desired.
-
use_next_split()[source]¶ Use the next split of the data into training and test data.
Returns True if more splits are available, otherwise False.
This method is useful for benchmarking
-
increase_split_number()[source]¶ Method for increasing split number (needed for access by meta nodes)
-
train_sweep(use_test_data)[source]¶ Performs the actual training of the node.
If use_test_data is True, we use all available data for training, otherwise only the data that is explicitly marked as data for training. This is a requirement e.g. for benchmarking.
-
process()[source]¶ Processes all data that is provided by the input node
Returns a generator that yields the data after being processed by this node.
-
request_data_for_training(use_test_data)[source]¶ Returns data for training of subsequent nodes of the node chain
A call to this method might involve training of the node chain up this node. If use_test_data is true, all available data is used for training, otherwise only the data that is explicitly for training.
-
request_data_for_testing()[source]¶ Returns data for testing of subsequent nodes of the node chain
A call to this node might involve evaluating the whole node chain up to this node.
-
test_retrain(data, label)[source]¶ Wrapper method for offline incremental retraining
The parameter retrain has to be set to True to activate offline retraining. The parameter buffering should be False, which is the default.
Note
The execute method of the node is called implicitly in this node instead of being called in the request_data_for_testing-method. For the incremental retraining itself the method _inc_train (to be implemented) is called.
For programming, we first train on the old data and then execute on the new one. This is necessary, since the following nodes may need the status of the transformation. So we must not change it after calling execute.
Note
Currently there is no retraining to the last sample. This could be done by modifying the
present_label()method and calling it in the last node after the last sample was processed.
-
present_label(label)[source]¶ Wrapper method for incremental training in application case (live)
The parameters retrain and buffering have to be set to True to activate this functionality.
For skipping examples, you can use None, “null” or an empty string as label.
Note
For the incremental training itself the method _inc_train (to be implemented) is called.
-
_batch_retrain(data_list, label_list)[source]¶ Interface for retraining with a set of data
A possible application is a calibration phase, where we may want to improve non-incremental algorithms.
If this method is not overwritten, it uses the incremental training as a default.
-
_change_parameters(parameters)[source]¶ Overwrite parameters of a node e.g. when it is loaded and parameters like retrain or recalibrate have to be set to True.
The node only provides the simple straight forward way, of permanently replacing the parameters. For more sophisticated parameter handling, nodes have to replace this method by their own.
-
store_state(result_dir, index=None)[source]¶ Stores this node in the given directory result_dir
This method is automatically called during benchmarking for every node. The standard convention is, that nodes only store their state, if the parameter store in the specification is set True.
-
replace_keywords_in_load_path()[source]¶ Replace keywords in the load_path parameter
Note
The keywords __INPUT_DATASET__ and __RESULT_DIRECTORY__ can also be used. The replacement of these keyword is done by the
NodeChainOperation.
-
get_previous_transformations(sample=None)[source]¶ Recursively construct a list of (linear) transformations
These transformations, applied on the data are needed later on for visualization. So the new classifier can be visualized relative to a previous linear processing step.
-
get_previous_execute(data, number=inf)[source]¶ Get execution from previous nodes on data
data should be forwarded to the previous number input nodes and the the result should be returned. By default, the data is recursively executed from the source node.
This function is needed for the implementation of the classifier application of the backtransformation concept, where the classifier function is kept in a state before transformation to track changes in the processing chain.
-
set_input_dim(n)[source]¶ Set input dimensions.
Perform sanity checks and then calls
self._set_input_dim(n), which is responsible for setting the internal attributeself._input_dim. Note that subclasses should overwrite self._set_input_dim when needed.
-
input_dim¶ Input dimensions
-
set_output_dim(n)[source]¶ Set output dimensions.
Perform sanity checks and then calls
self._set_output_dim(n), which is responsible for setting the internal attributeself._output_dim. Note that subclasses should overwrite self._set_output_dim when needed.
-
output_dim¶ Output dimensions
-
_train_seq¶ List of tuples:
[(training-phase1, stop-training-phase1), (training-phase2, stop_training-phase2), ...]
By default:
_train_seq = [(self._train, self._stop_training)]
-
get_current_train_phase()[source]¶ Return the index of the current training phase.
The training phases are defined in the list self._train_seq.
-
get_remaining_train_phase()[source]¶ Return the number of training phases still to accomplish.
If the node is not trainable then return 0.
-
_pre_execution_checks(x)[source]¶ This method contains all pre-execution checks.
It can be used when a subclass defines multiple execution methods.
-
execute(x, in_training=False, *args, **kwargs)[source]¶ Project the data by using matrix product with the random matrix
This node has been automatically generated by wrapping the sklearn.random_projection.SparseRandomProjection class from the
sklearnlibrary. The wrapped instance can be accessed through thescikit_algattribute.Parameters
- X : numpy array or scipy.sparse of shape [n_samples, n_features]
- The input data to project into a smaller dimensional space.
y : is not used: placeholder to allow for usage in a Pipeline.
Returns
- X_new : numpy array or scipy sparse of shape [n_samples, n_components]
- Projected array.
-
train(x, *args, **kwargs)[source]¶ Update the internal structures according to the input data x.
x is a matrix having different variables on different columns and observations on the rows.
By default, subclasses should overwrite _train to implement their training phase. The docstring of the _train method overwrites this docstring.
Note
A subclass supporting multiple training phases should implement the same signature for all the training phases and document the meaning of the arguments in the _train method doc-string. Having consistent signatures is a requirement to use the node in a node chain.
-
stop_training(*args, **kwargs)[source]¶ Generate a sparse random projection matrix
This node has been automatically generated by wrapping the sklearn.random_projection.SparseRandomProjection class from the
sklearnlibrary. The wrapped instance can be accessed through thescikit_algattribute.Parameters
- X : numpy array or scipy.sparse of shape [n_samples, n_features]
- Training set: only the shape is used to find optimal random matrix dimensions based on the theory referenced in the afore mentioned papers.
y : is not used: placeholder to allow for usage in a Pipeline.
Returns
self
-
__call__(x, *args, **kwargs)[source]¶ Calling an instance of Node is equivalent to calling its execute method.
-
__hyperparameters= set([NoOptimizationParameter<kwargs_warning>, NoOptimizationParameter<dtype>, NoOptimizationParameter<output_dim>, NoOptimizationParameter<retrain>, NoOptimizationParameter<input_dim>, NoOptimizationParameter<store>])¶
-
__weakref__¶ list of weak references to the object (if defined)
-
input_types= ['TimeSeries', 'FeatureVector', 'PredictionVector']¶
-
copy(protocol=None)[source]¶ Return a deep copy of the node.
Parameters: protocol – the pickle protocol (deprecated).